This was one of the more important mindset changes in the whole repo, and it was not really about UI labels. It was about honesty.
For a while, like a lot of tools, A11Y Cat could have gotten away with treating “issue” as one big category. You run checks, you find problems, you show them in a list. That is simple, and it sounds confident.
The trouble is that the repo had already moved far beyond one kind of result. By April it had axe findings, product-deterministic checks, heuristics, manual review prompts, diagnostics, AI-assisted output, and various cases where the tool knew something interesting but could not honestly call it a confirmed defect.
At that point, forcing everything into one bucket would have made the product easier to read and harder to trust.
That is why the later April work around issue types and trust modeling matters so much. The README starts talking about deterministic failures, corroborated failures, engine-limited reviews, state-limited reviews, visual-composition reviews, human-judgement reviews, and advisory notes. The runtime gets issue-types.js, trust-model.js, updated rendering logic, and tests that check the classifications across runtime, exports, and UI defaults.
I think this is one of the moments where the repo visibly grows up. It is easy to add more checks. It is harder to tell users that not all outputs deserve the same tone or weight.
The trust model work also makes the rest of the system cleaner. Once issue classes are explicit, exports can preserve them. AI can be framed relative to them. Diagnostics can sit beside them without being mistaken for findings. The release-readiness logic can reason about them. The tool’s language becomes more consistent because the underlying categories become more consistent.
What I find most convincing is that the repo does not use these categories to hide uncertainty. It does the opposite. The categories mostly exist so uncertainty stops getting smuggled into the same visual and export channel as confirmed evidence.
That is a real accessibility-tooling lesson. If a tool cannot clearly separate “we know this” from “this needs review” from “this is advisory,” people either misread it or stop trusting it. Neither is good.
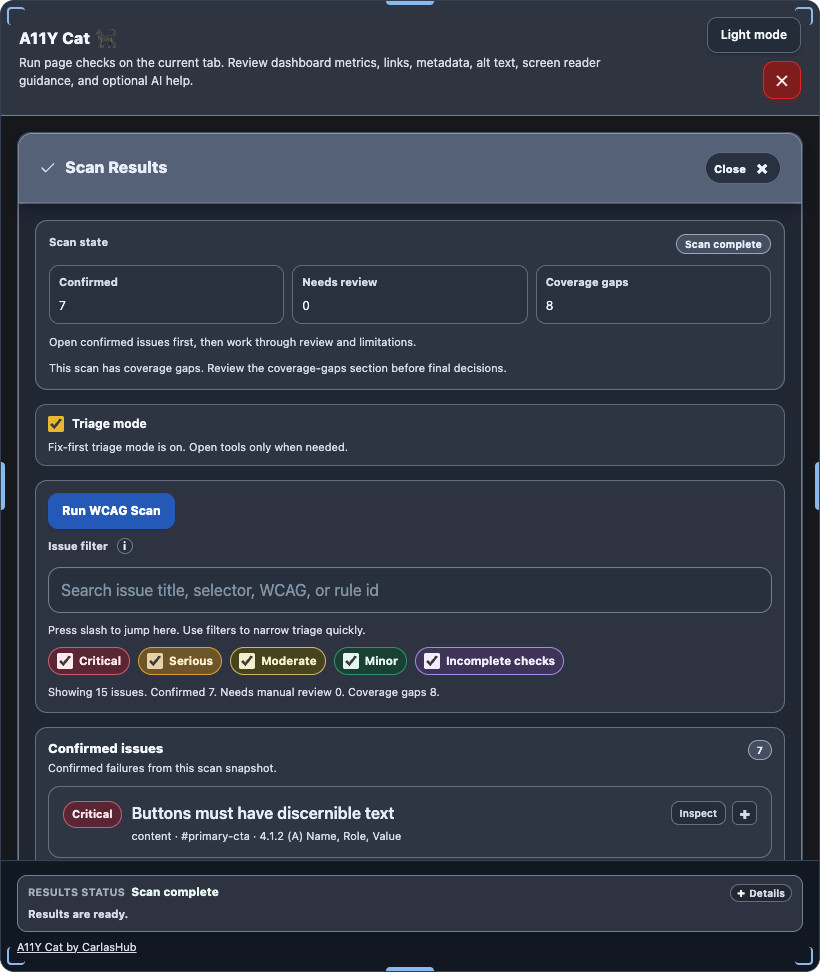
Visual evidence
The issue-type split is mostly a modeling and rendering-language change, so there is no single screenshot that proves it on its own. The nearest visible surface is the grouped scan-results panel where those distinctions become user-facing:
What I was really learning here
I was learning that cleaner output is not always better output. Sometimes the honest thing is to let the model of the world get more complicated so the tool stops flattening very different kinds of evidence into one voice.
Evidence
- Commits:
27afee8– runtime, taxonomy, and release gate updates shipped together4425e4a– truth-model-only active flows enforced0bf2129– product-wide trust classification with AI-assisted provenancea6c11f2– explicit trust classification across findings, AI output, and comparison exports
- Files:
../../src/runtime/modules/issue-types.js../../src/runtime/modules/trust-model.js../../src/runtime/modules/ui-rendering.js../../src/runtime/modules/exports.js../../tests/node/runtime-modules.test.js../../README.md
