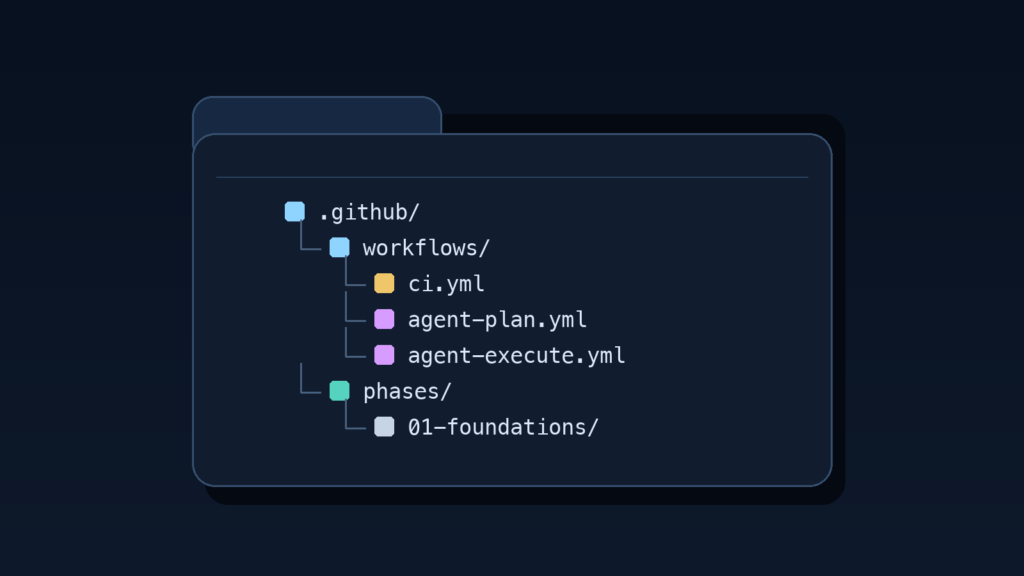
journal / github-actions-professional-agentic-development
GitHub Actions Agentic Development Guide
A practical GitHub Actions guide covering first workflows, CI, manual runs, logs, debugging, permissions, secrets, and safe automation habits.

Carla Goncalves
Mostly things I work on, test, fix, or think about.
Web Developement x A11Y x Design x AI x Tools
RECENT POSTS
The newest posts on the site.
journal / github-actions-professional-agentic-development
A practical GitHub Actions guide covering first workflows, CI, manual runs, logs, debugging, permissions, secrets, and safe automation habits.
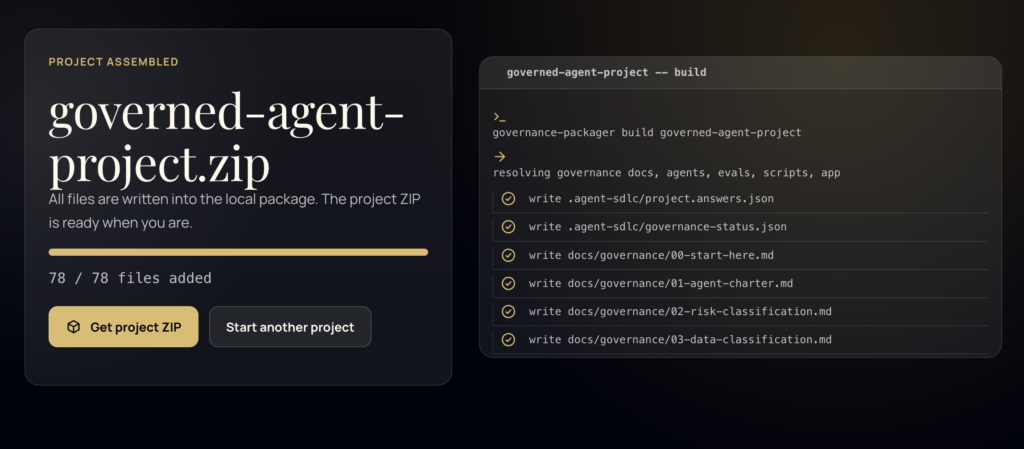
journal / ai-agent-sdlc-boilerplate-governance
A practical AI-Agent SDLC boilerplate for setting up governance, scope, data boundaries, tool access, approval gates, evidence rules, eval cases, and release checks before agents start implementation.
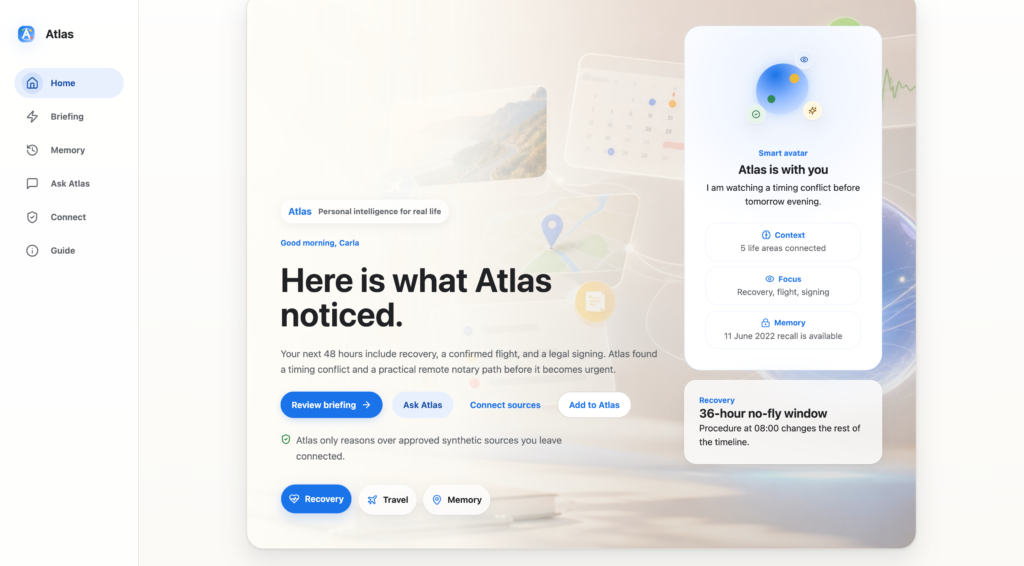
journal / i-built-atlas-ambient-life-intelligence
Atlas is an Ambient Life Intelligence prototype that explores how AI agents can connect approved signals, evidence, memory, and user control.

journal / how-to-build-a-website-with-ai-agents-without-letting-them-run-wild
A technical, plain-language guide to agentic development, AI agent teams, governance, framework choices, real workflows, and why companies are moving from assistants to governed agents.

journal / mcp-servers-explained-for-normal-people
A plain-language guide to MCP servers, Model Context Protocol, and how AI agents connect to tools like Figma, GitHub, DevTools, docs, databases, Jira, Drive, and local files.

journal / gh600-agentic-ai-study-platform
A practical GH-600 Agentic AI Study Platform with lessons, quizzes, labs, flashcards, scenarios, and an exam simulator for GitHub Copilot, MCP, guardrails, evaluation, and responsible AI.
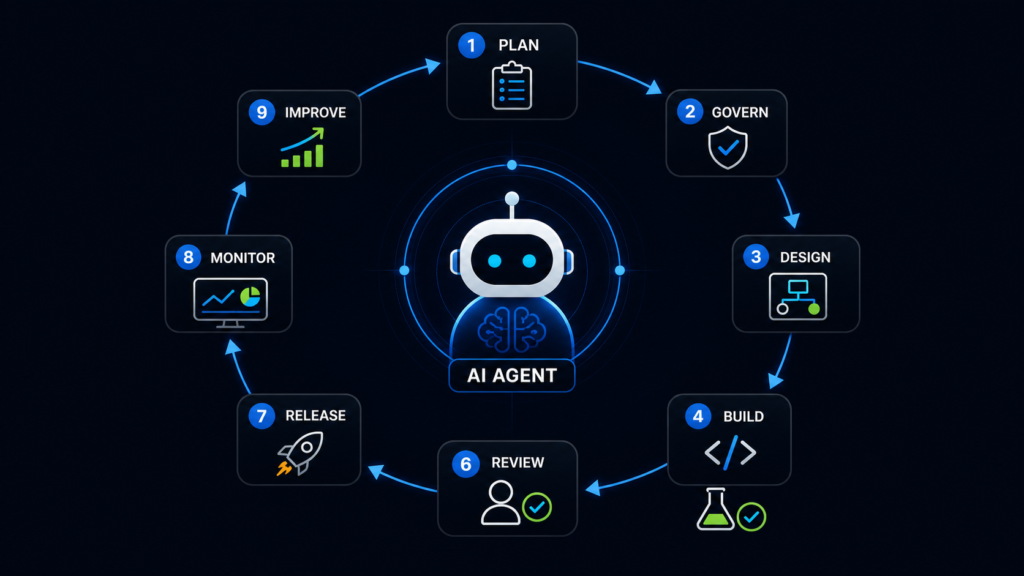
journal / ai-agent-sdlc-practical-lifecycle-building-operating-ai-agents-safely
AI agents should not be treated as magic workers that can freely read files, call tools, change code, query systems, create pull requests, send messages, or deploy changes without structure. An AI agent is…
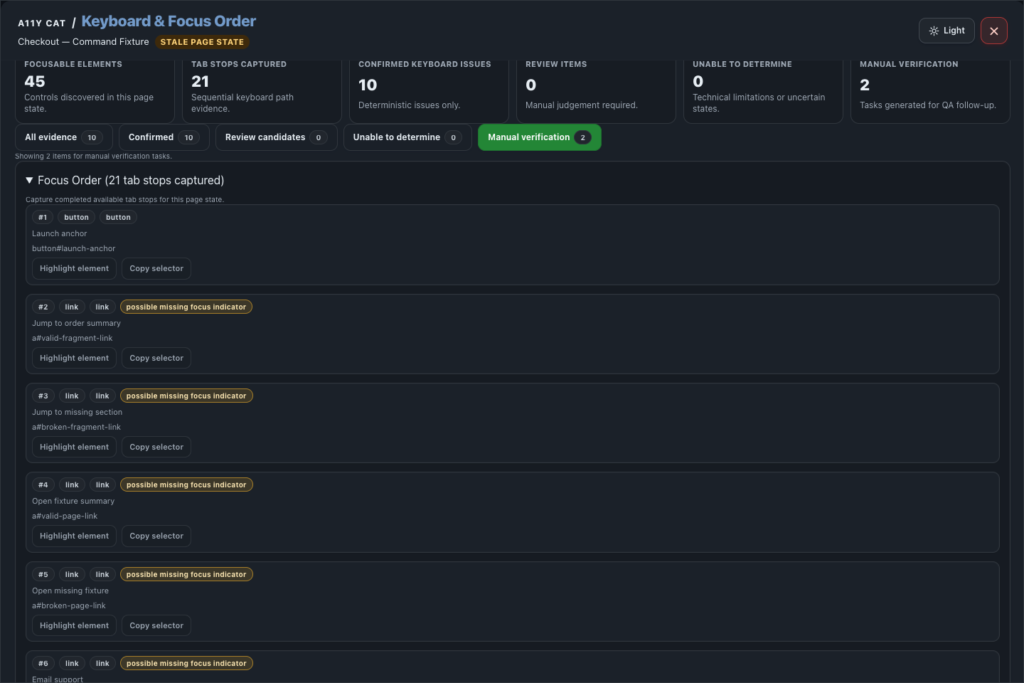
journal / a11y-cat-keyboard-focus-order-feature-tour
Keyboard and Focus Order is the evidence area for focusable element discovery, sequential tab-stop capture, deterministic focus findings, manual verification, and exportable focus evidence. A list of focusable elements is useful, but it is…
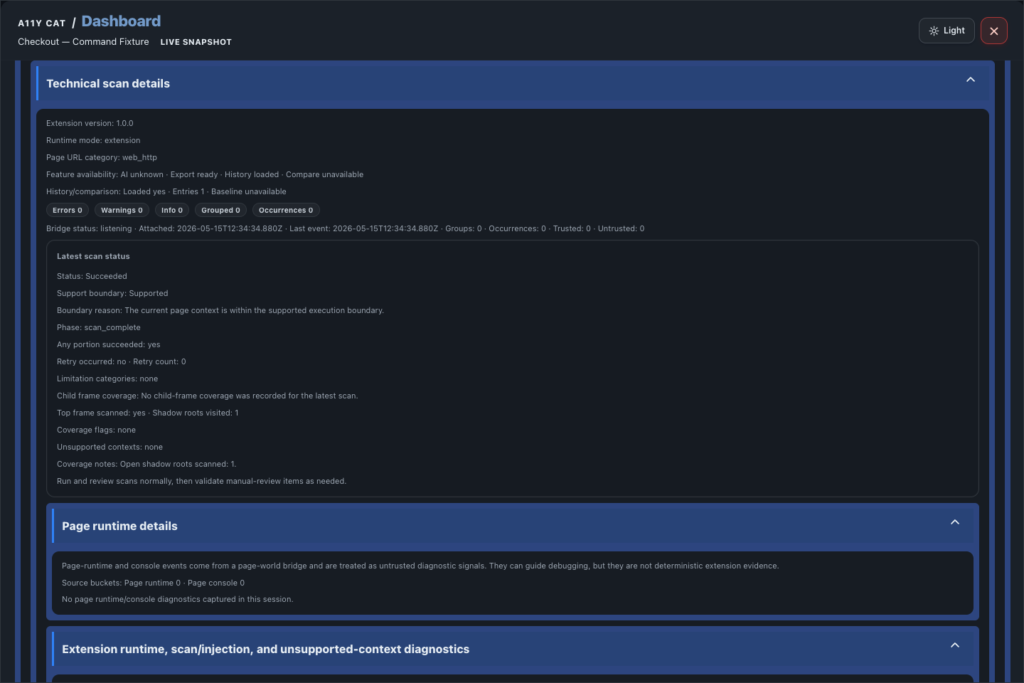
journal / a11y-cat-dashboard-feature-tour
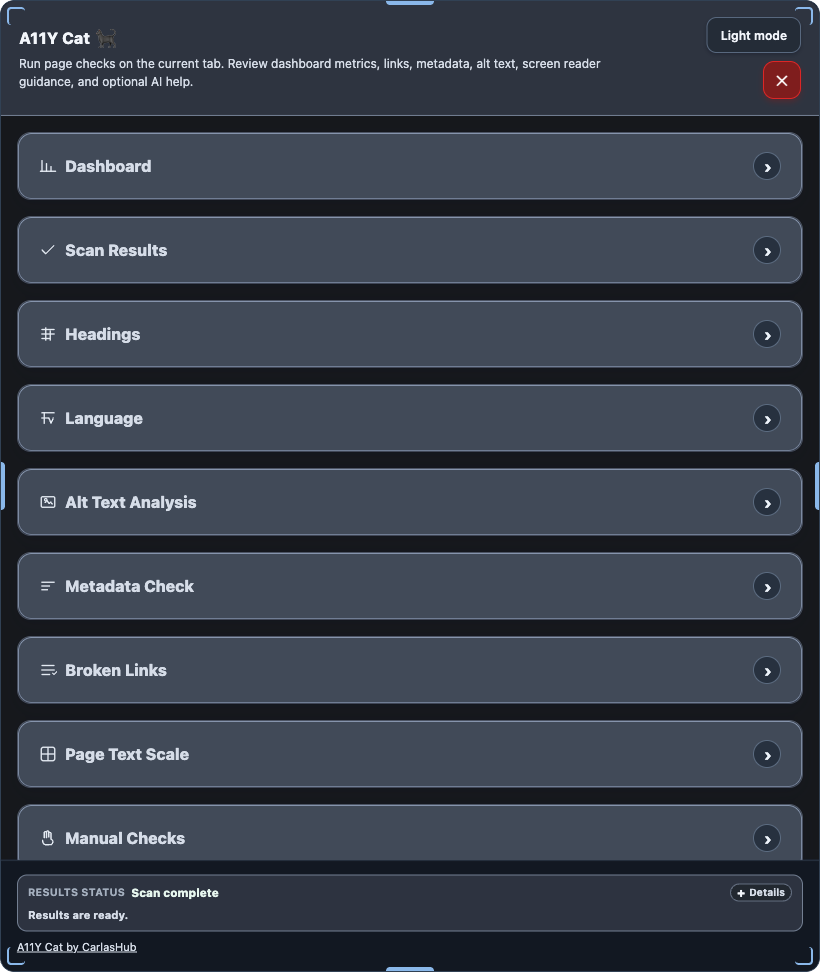
The Dashboard is the reviewer’s starting point. It tells you what was scanned, what evidence exists, whether the current page state is fresh, and what should happen next. I do not want this screen…
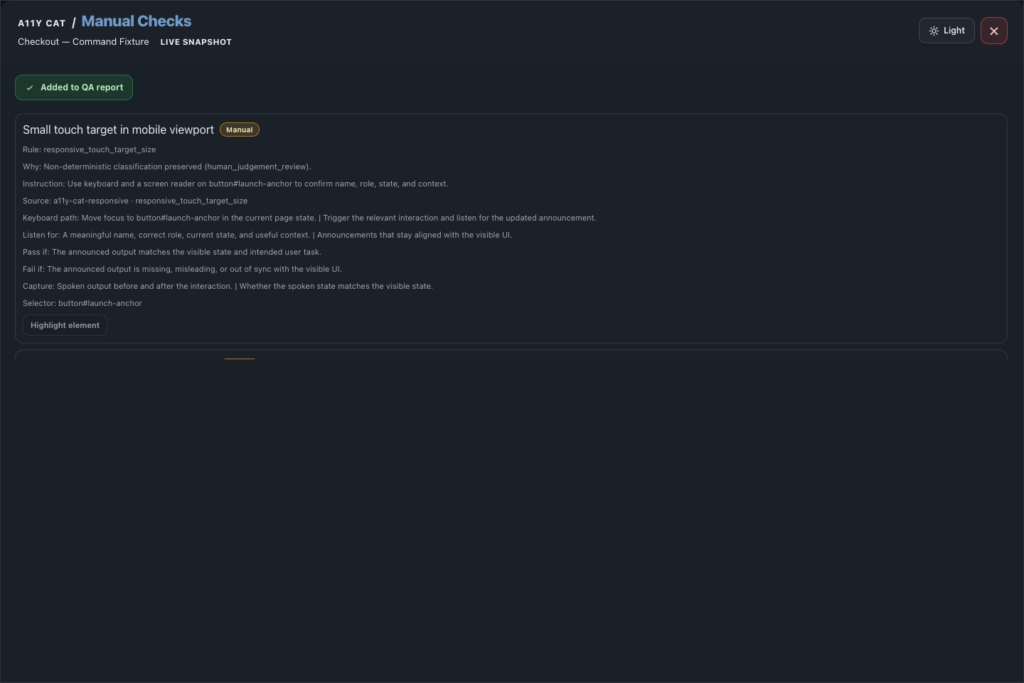
journal / a11y-cat-manual-checks-feature-tour
Manual Checks is the review queue for checks automation cannot safely classify, including tester instructions, expected observations, selectors, and evidence requirements. This section is where the extension refuses to bluff. If something needs a…
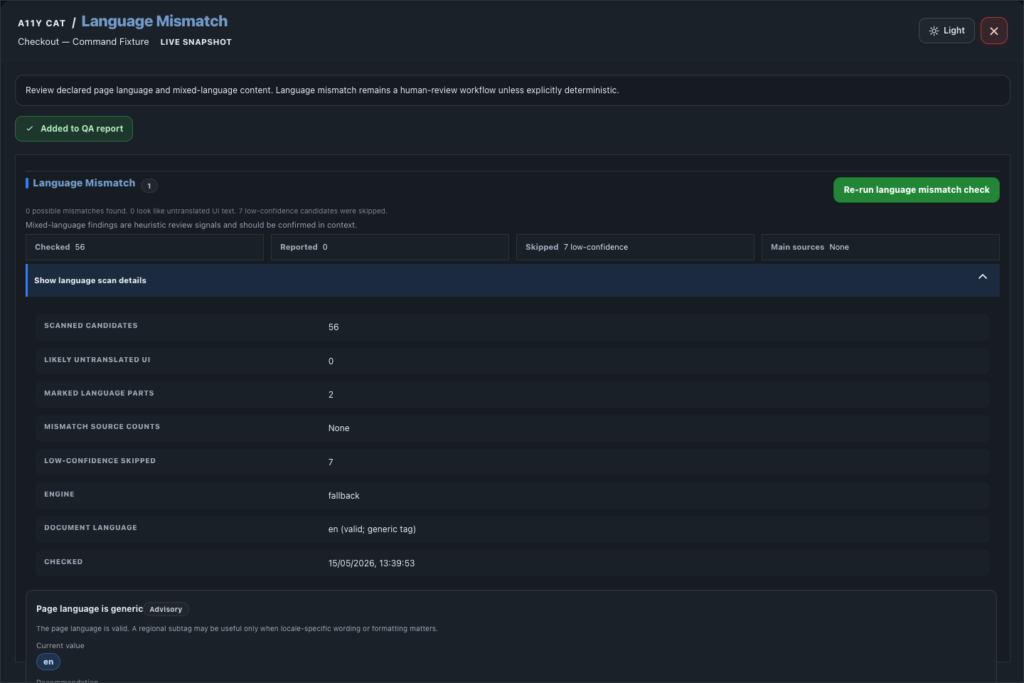
journal / a11y-cat-language-mismatch-feature-tour
Language Mismatch reviews declared page language, visible mixed-language evidence, inline language signals, and confidence-bound output. Language detection can get messy quickly, especially with short labels, names, product terms, and mixed-language content. This section is…
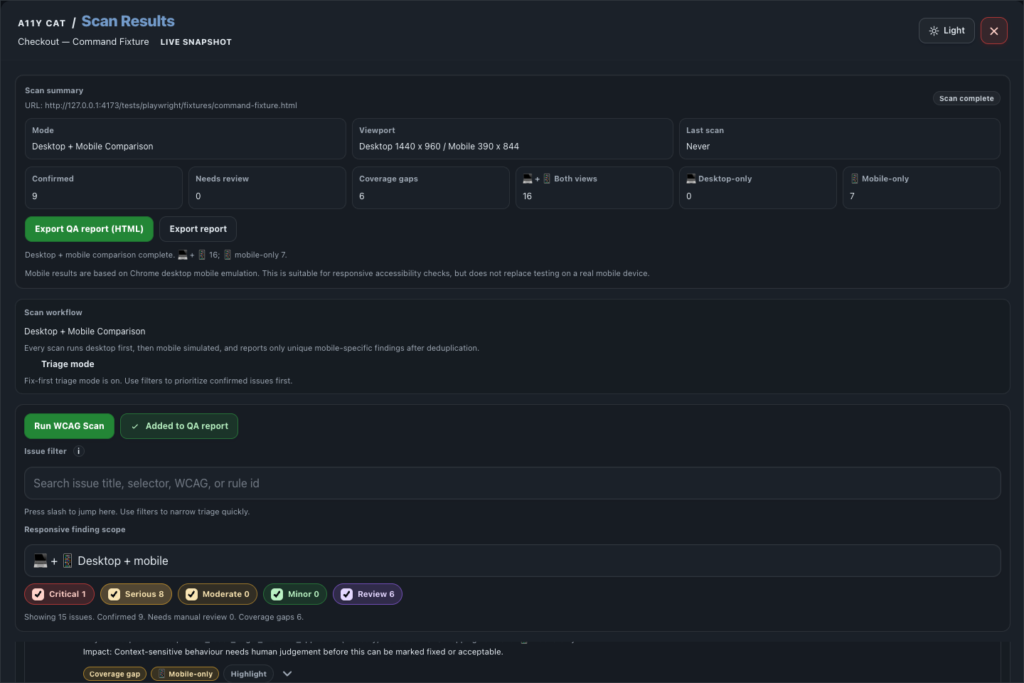
journal / a11y-cat-scan-results-feature-tour
Scan Results is the main triage surface. It turns automated WCAG findings, responsive comparison data, and issue evidence into something a reviewer can verify and hand off. This area exists because a raw axe…
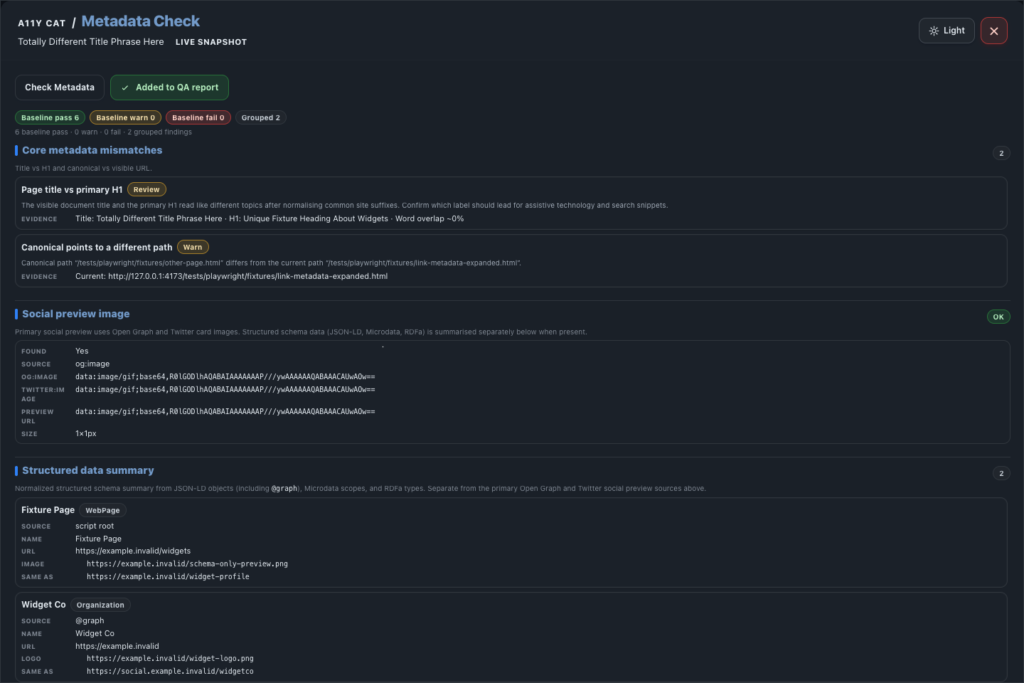
journal / a11y-cat-metadata-check-feature-tour
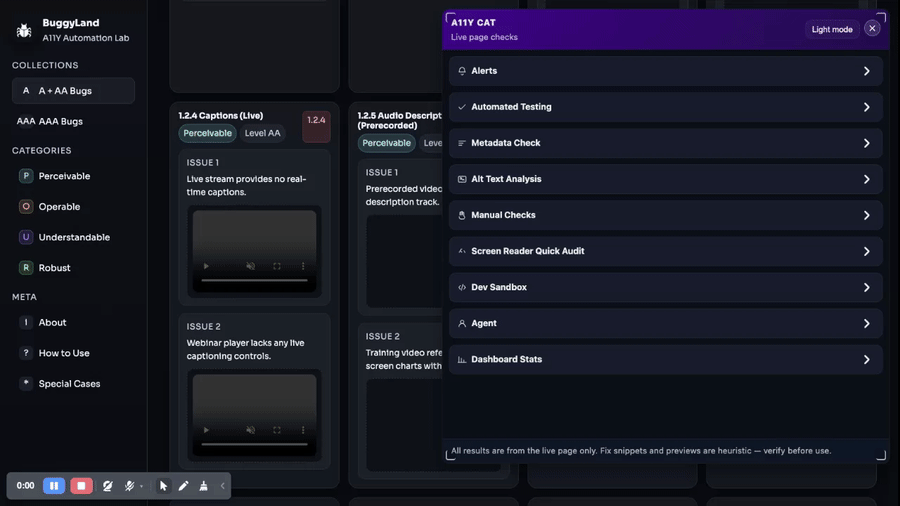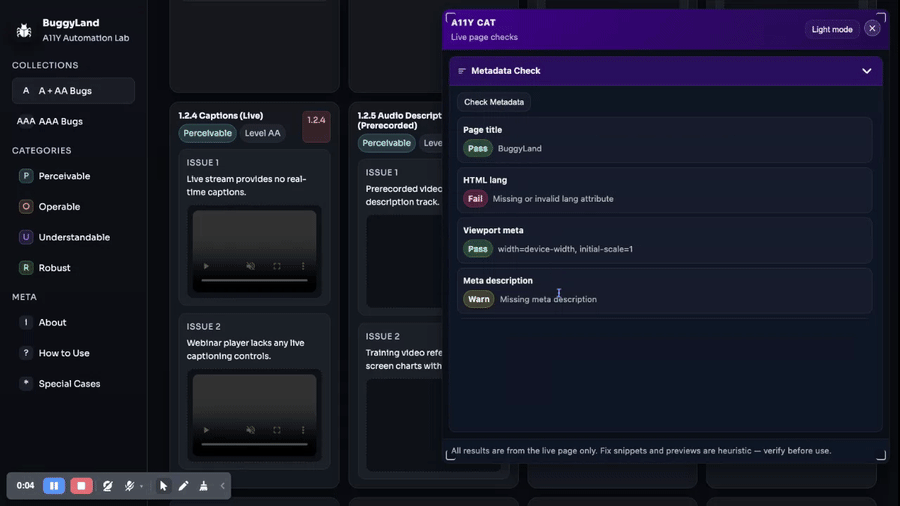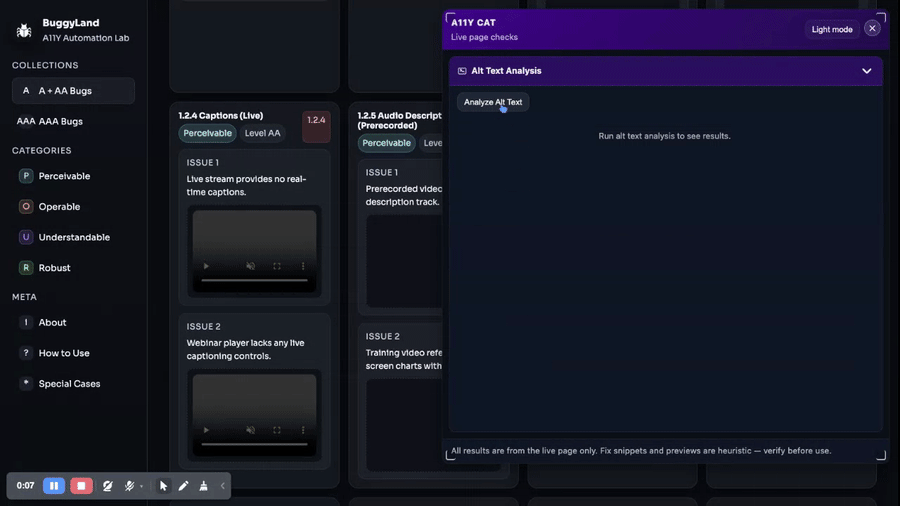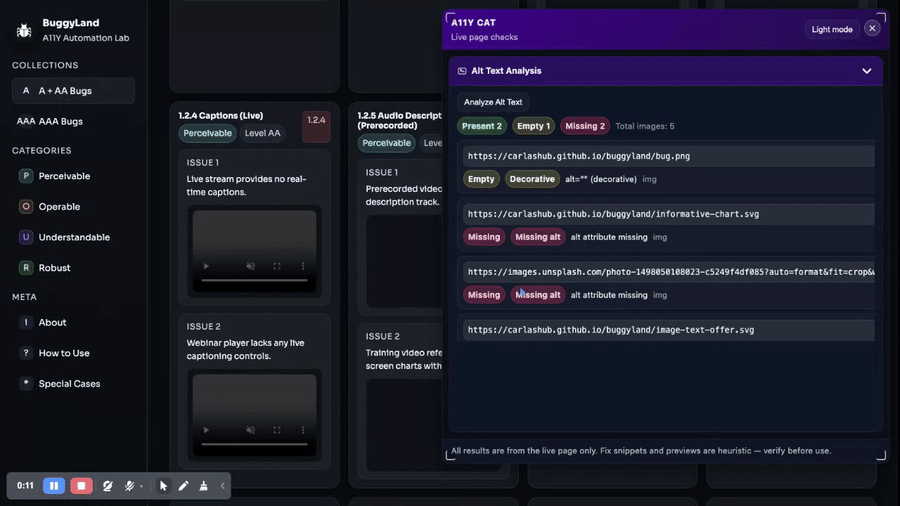
Metadata Check reviews page title, H1/title relationship, canonical URL, social preview metadata, structured data, viewport metadata, and baseline document signals. Good metadata helps people understand where they are, helps teams share the right page,…

journal / my-google-chrome-web-store-submission-prompt
The strict final A11Y Cat Chrome Web Store submission prompt I use to test the MV3 extension package, scanner trust, privacy, documentation, UI, and release process before beta or public submission.
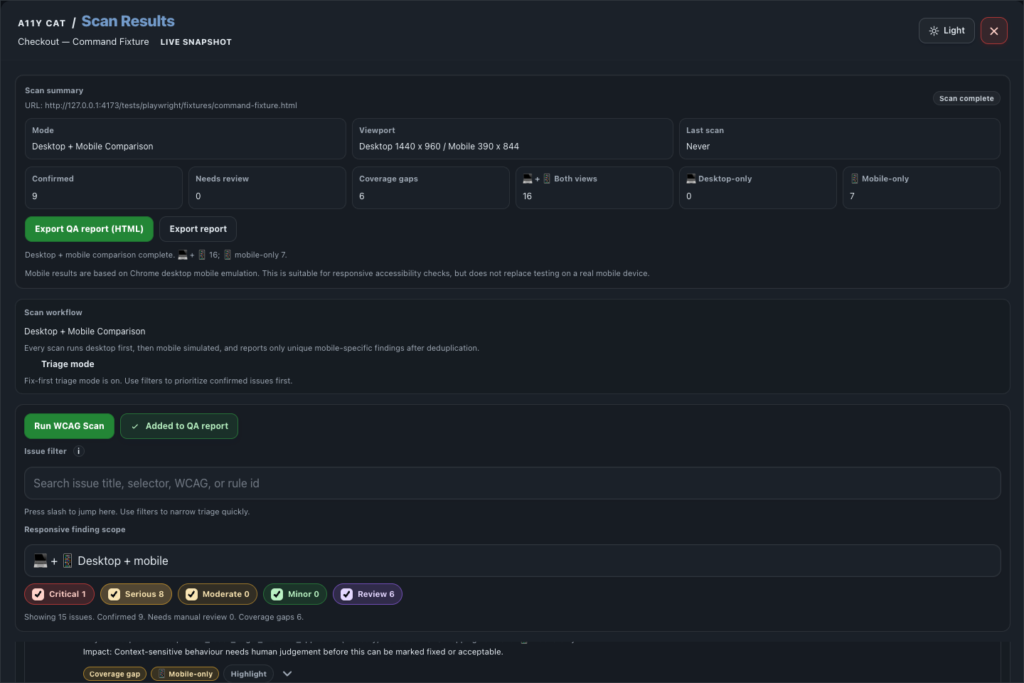
journal / a11y-cat-reports-exports-developer-handoff-feature-tour
Reports, Exports, and Developer Handoff turn working evidence into material another person can read, reproduce, archive, and act on. The best accessibility report is not the longest one. It is the one that keeps…
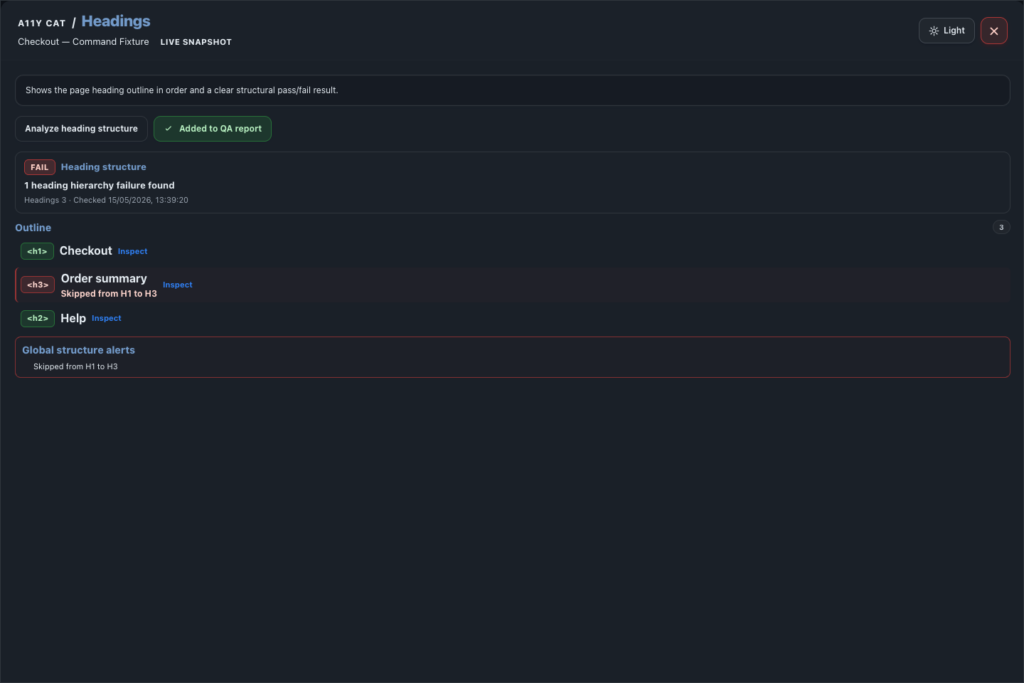
journal / a11y-cat-headings-feature-tour
Headings is the structure review area for ordered outline analysis, visible H1 checks, hidden or empty headings, skipped levels, duplicates, and semantic heading risks. This section is about structure, not visual size. A page…
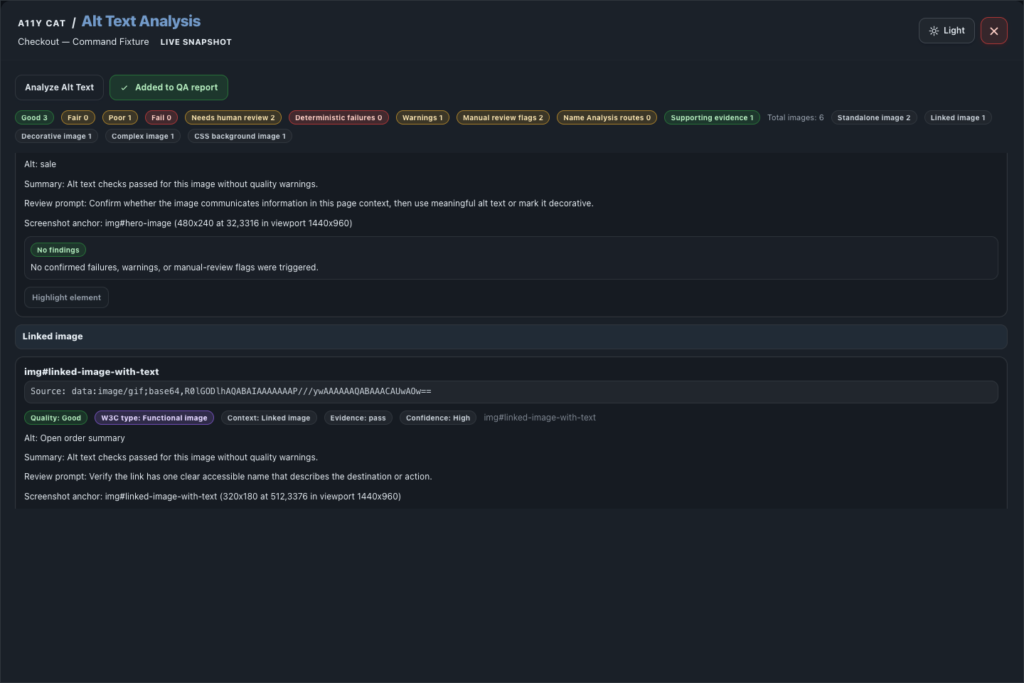
journal / a11y-cat-alt-text-analysis-feature-tour
Alt Text Analysis reviews image alternatives, decorative image evidence, context-dependent alt quality, and the limits of manual image judgement. Alt text is not just a missing-attribute hunt. Sometimes empty alt is right. Sometimes an…
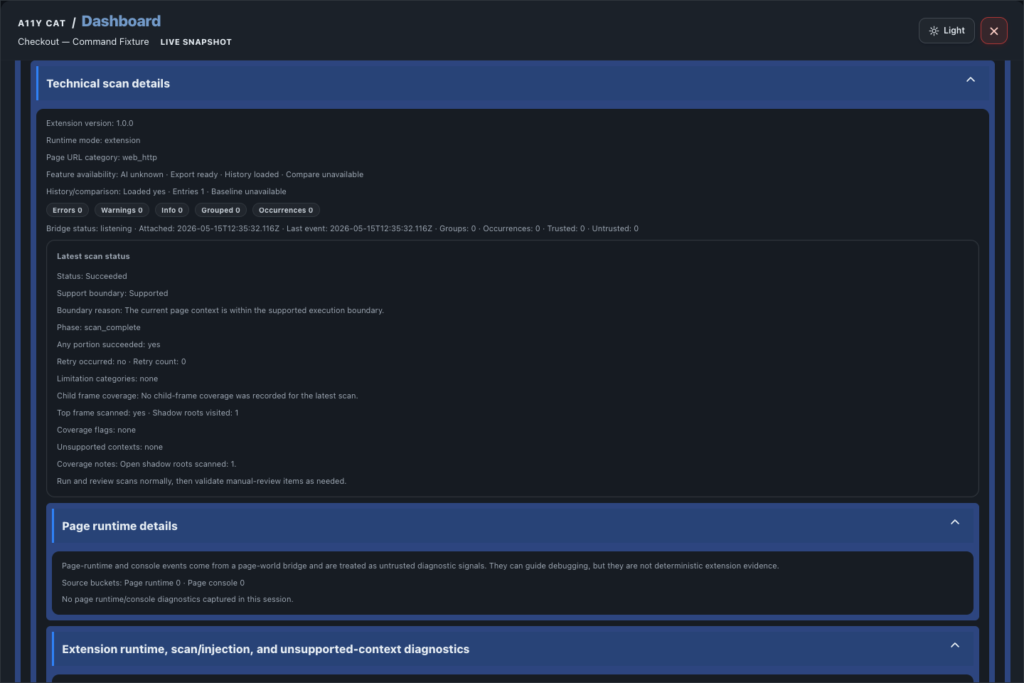
journal / a11y-cat-local-history-comparison-feature-tour
Local History and Comparison answer a practical question: did this page get better, worse, or simply different since the last comparable scan? This is one of the places where the extension has to be…
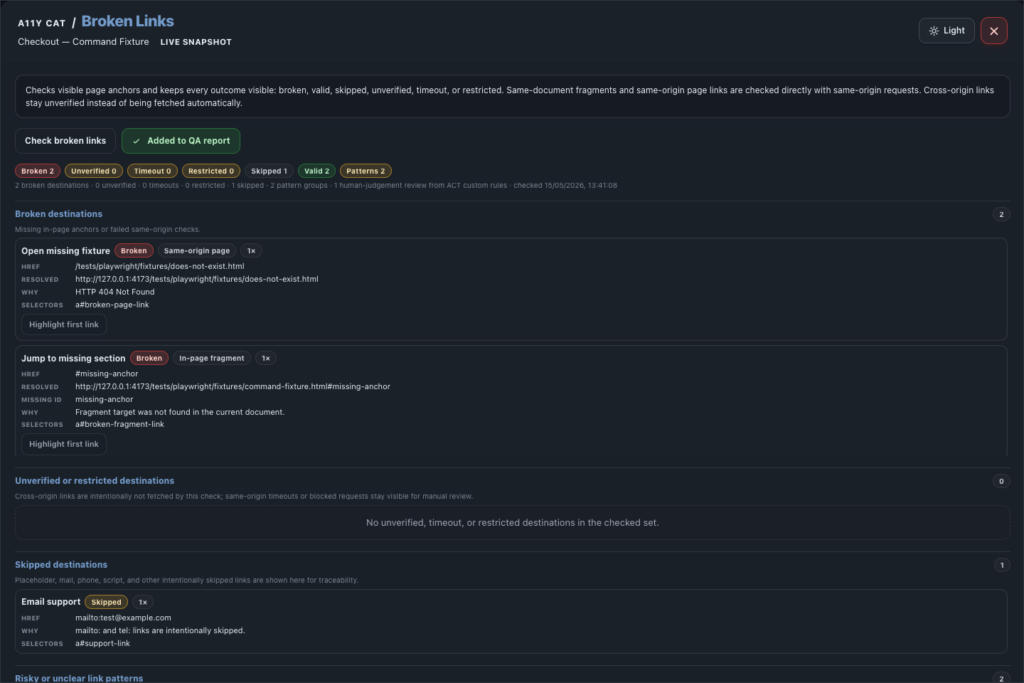
journal / a11y-cat-broken-links-feature-tour
Broken Links checks visible anchors and classifies same-document, same-origin, cross-origin, valid, broken, skipped, unverified, timeout, restricted, and risky outcomes. A broken link is simple only when it is obviously broken. Browser extensions also run…
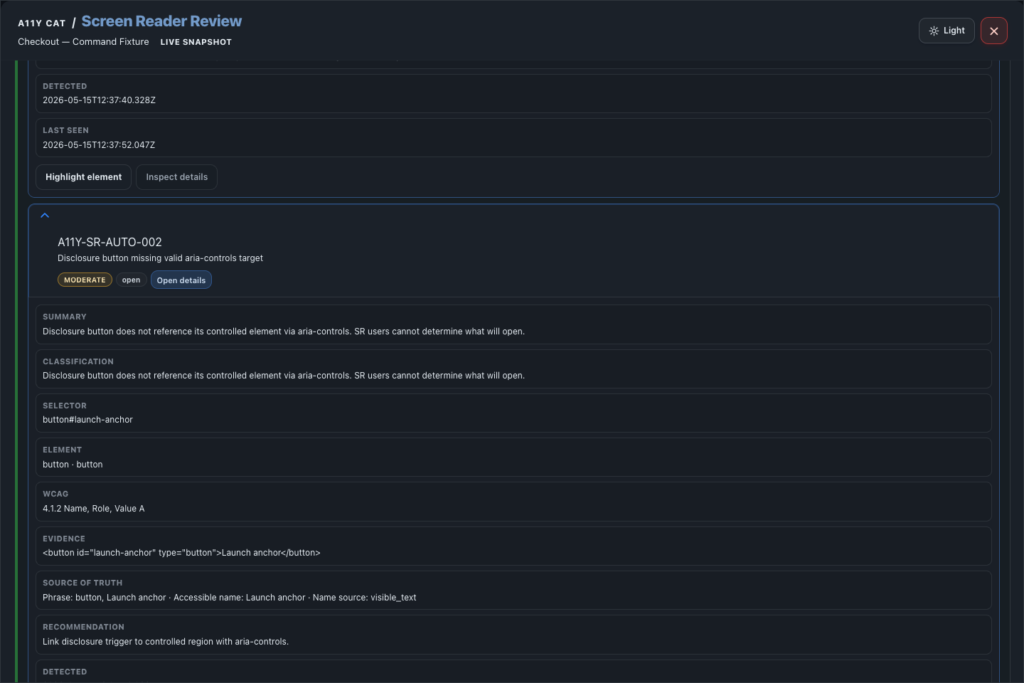
journal / a11y-cat-screen-reader-review-feature-tour
Screen Reader Review is a Guidepup-supported virtual screen-reader workspace for spoken-output evidence, structured review, diagnostics, and QA handover. The most important thing about this feature is honesty. It can help a reviewer prepare, compare…
journal / making-a11y-cat-trustworthy
What I learned while debugging an accessibility scanner with AI agents, and why evidence matters more than pass/fail theatre.
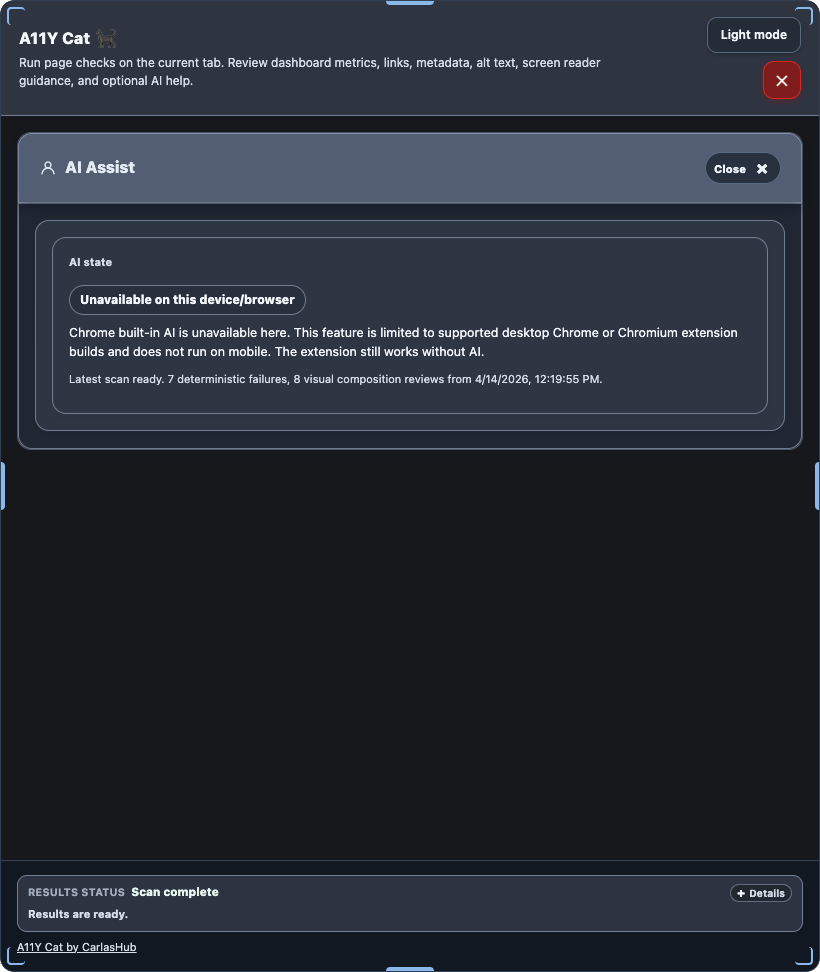
journal / why-im-not-building-a11y-cat-around-paid-accessibility-apis
A practical look at WAVE API, axe-core, Playwright, Pa11y, IBM Equal Access, and why a local scanner is the more honest foundation for A11Y CAT.
journal / cat-crawler-why-i-built-it-what-i-learned
Why I built Cat Crawler, what it is good at, what it taught me, and the improvements I would make next.
journal / a11y-cat-agents-workflow-best-practices-for-developers
What it takes to use agents without letting the work slip into vague claims, fake certainty, or sloppy release habits.
journal / wordpress-ai-accessibility-reality
A look at the way people are talking about WordPress and AI, and why accessibility still gets flattened or ignored in that conversation.
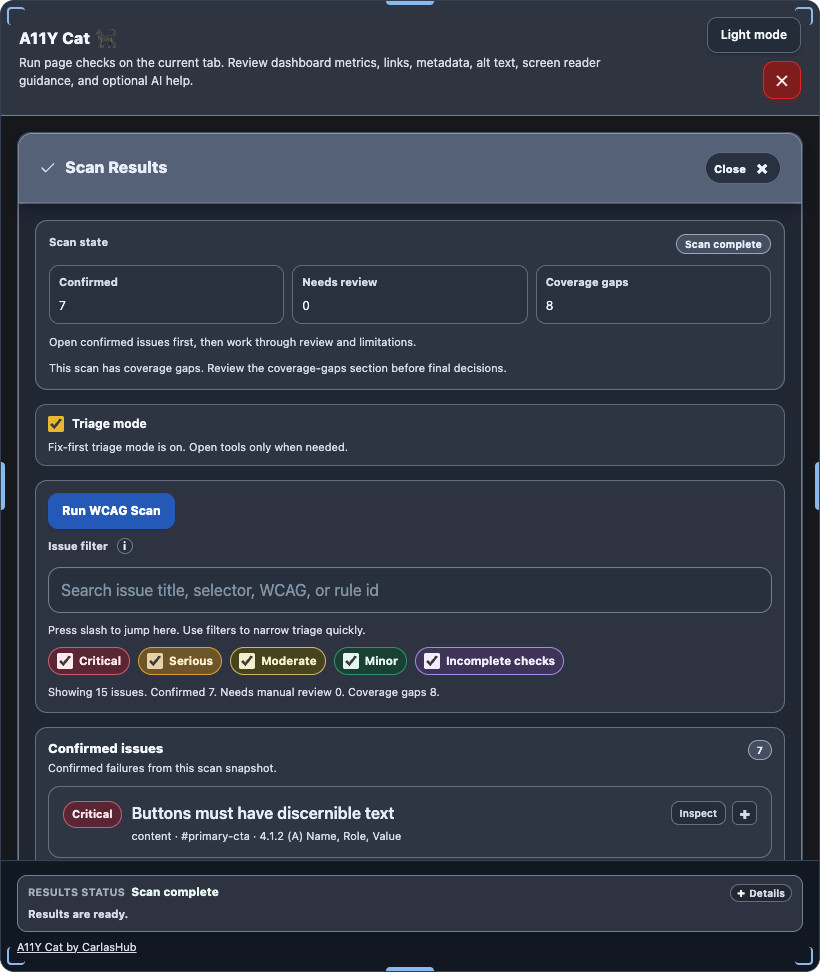
journal / a11y-cat-25-what-this-project-is-now
A plain account of where the project stands now, what it can actually prove, and where the limits still are.
journal / a11y-cat-24-governing-the-work-as-hard-as-the-code
Why the project started leaning harder on rules, release discipline, and explicit boundaries instead of good intentions.
journal / a11y-cat-23-packaging-and-handoff-tooling
Packaging, release handoff, and build cleanup stopped being side work once the project got big enough to ship properly.

journal / a11y-cat-22-cutting-seams-into-the-runtime
This was probably inevitable. The only question was whether I was going to admit it early enough. By mid-April, A11Y Cat’s runtime had become too large and too central to keep pretending one file…
journal / a11y-cat-16-language-headings-and-structure
These are the kinds of features that sound small until you try to make them useful on real pages without being annoying. Language, headings, and structure work are scattered across A11Y Cat’s later history,…
journal / a11y-cat-21-measuring-detection-quality
This was a big shift in what “tested” meant to me. There is a difference between testing that a tool runs and testing that it keeps finding the right things. A11Y Cat eventually starts…
journal / a11y-cat-14-the-tool-got-wider-before-it-got-deeper
A lot of the middle history is me adding more surfaces around the main scan because real review work kept asking for them. If I had to describe one broad pattern in A11Y Cat…
journal / 13-moving-toward-on-device-ai
The later AI work feels much less like “let the model help everywhere” and much more like “if AI is here, it needs to fit inside the product’s boundaries.” After the early Groq and…
journal / 11-release-vs-test-extension
This is one of those engineering details that sounds boring until you realise it is protecting the truth of the whole release story. One of the smarter moves in this repo is that the…
journal / a11y-cat-20-diagnostics-and-boundaries
This is one of the clearest places where the repo stopped treating failure handling as an afterthought. A lot of browser tools quietly act embarrassed when something fails. They either show a vague error,…
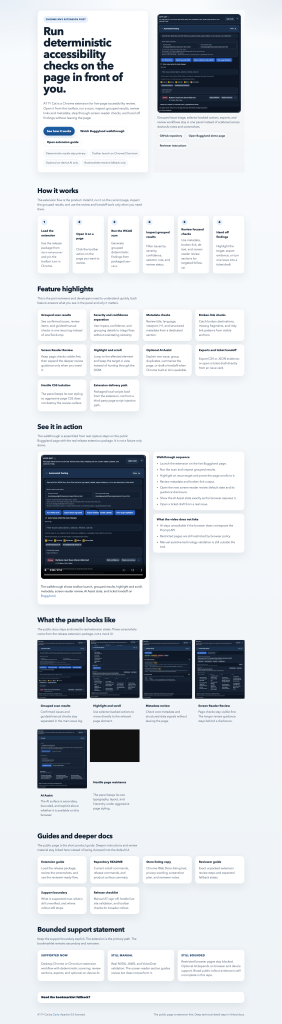
journal / 09-the-extension-pivot
Once I started looking at the extension commits closely, it stopped feeling like “another way to launch the tool” and started feeling like a different phase of the product. The bookmarklet and the extension…

journal / 08-the-bookmarklet-hit-a-wall
This was one of those moments where the main limitation was not the audit logic. It was how the tool reached the page at all. I still think the bookmarklet was a good place…
journal / a11y-cat-19-history-baselines-and-local-state
This is where the project starts moving from “run a scan now” toward “use the tool as part of an ongoing review process.” There is a stage in browser tooling where one-off scans stop…
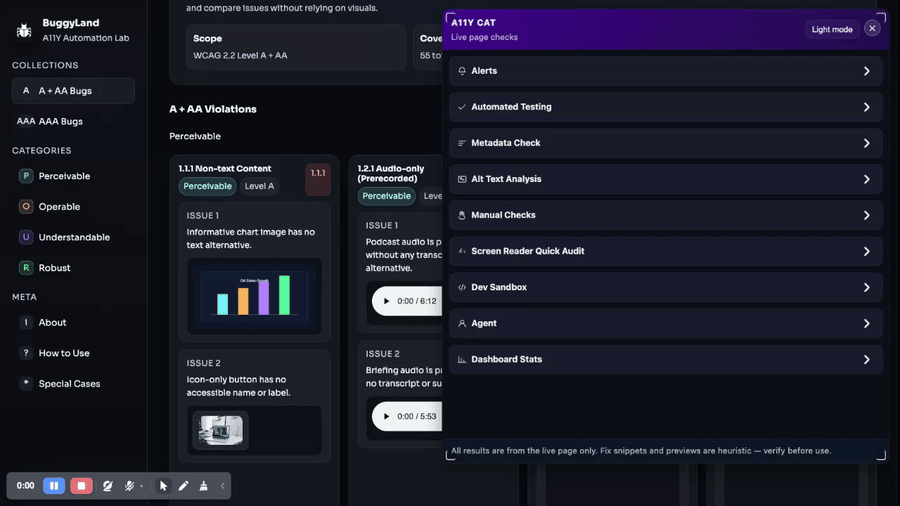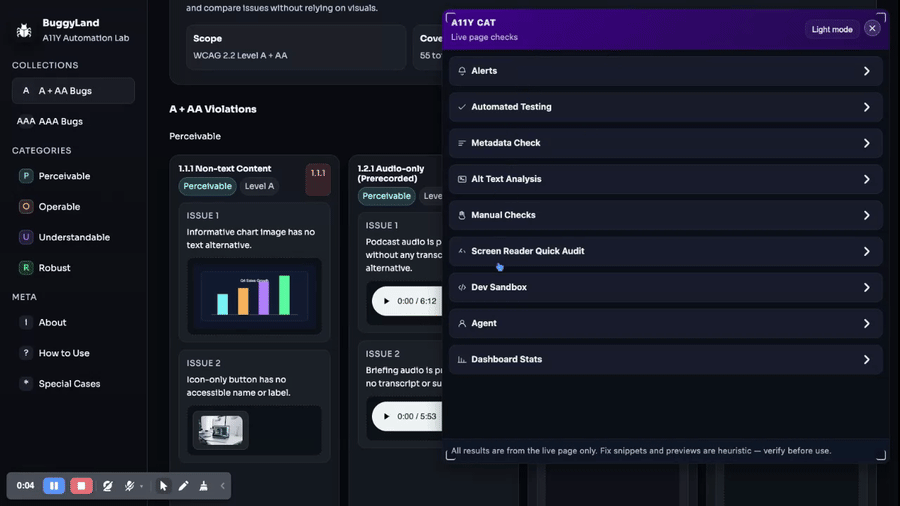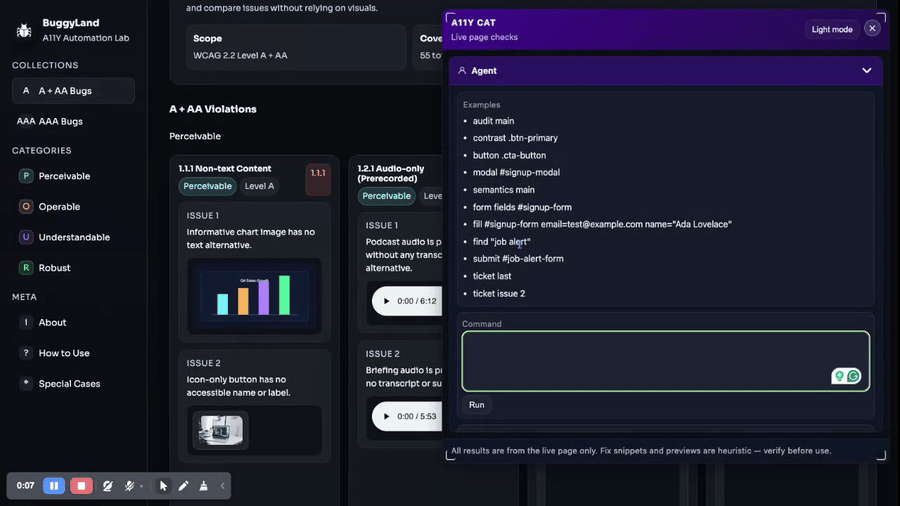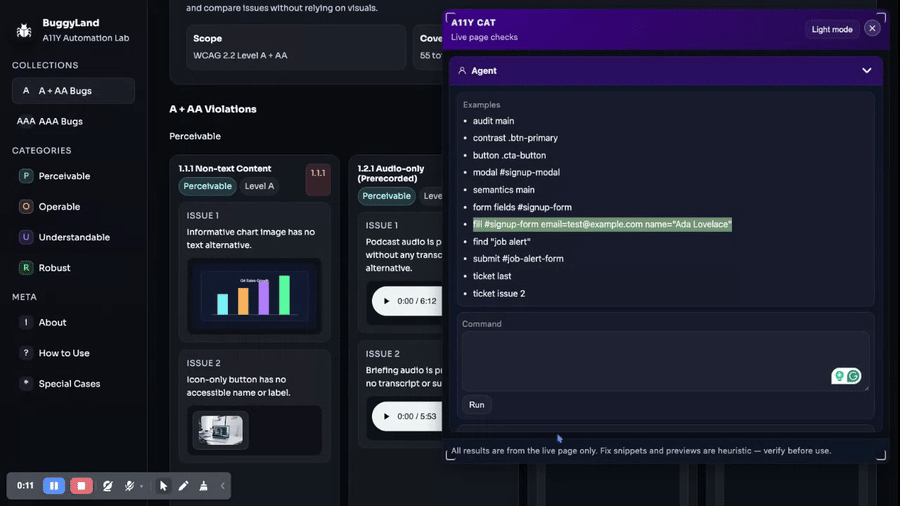
journal / 05-my-first-ai-phase-was-still-experimental
I can see the enthusiasm in this stage, but I can also see that I had not settled the trust story yet. The first AI phase in this repo lands fast. On February 16…
journal / 04-why-i-spent-so-much-time-on-demos
At first glance it looks like I got distracted by GIFs. Looking back, I think I was trying to make the tool legible. February 16 is one of the strangest-looking days in the repo…