A lot of the middle history is me adding more surfaces around the main scan because real review work kept asking for them.
If I had to describe one broad pattern in A11Y Cat before the later hardening phase, it would be this: the tool kept getting wider.
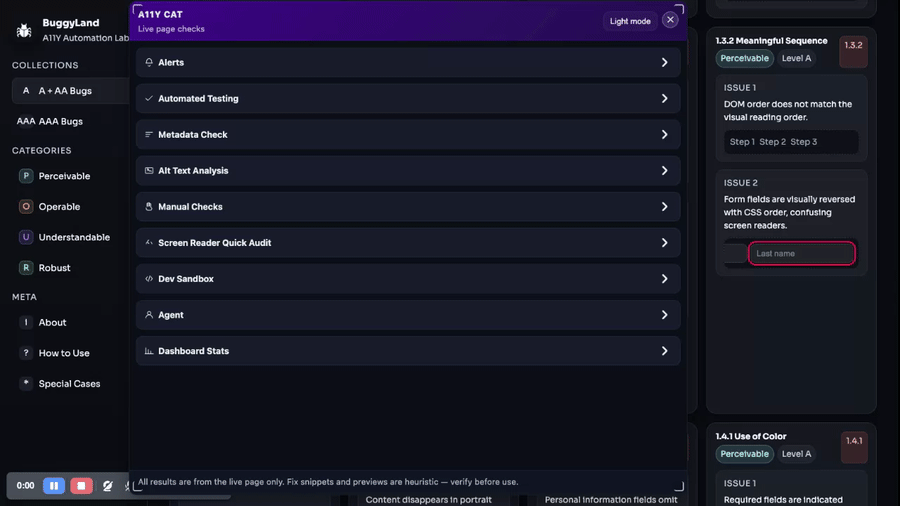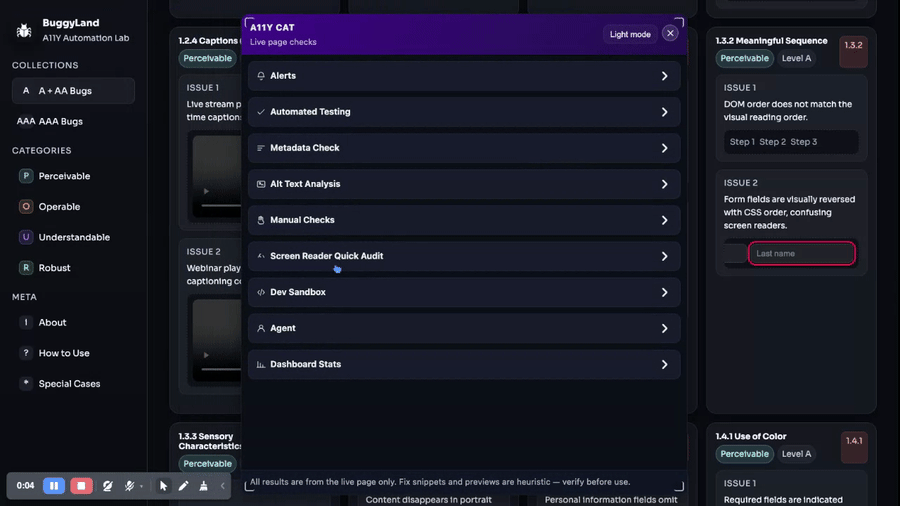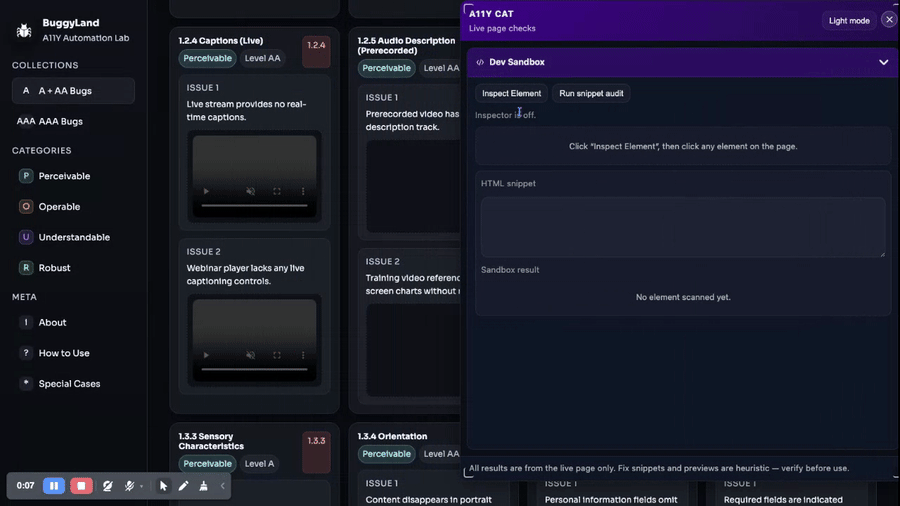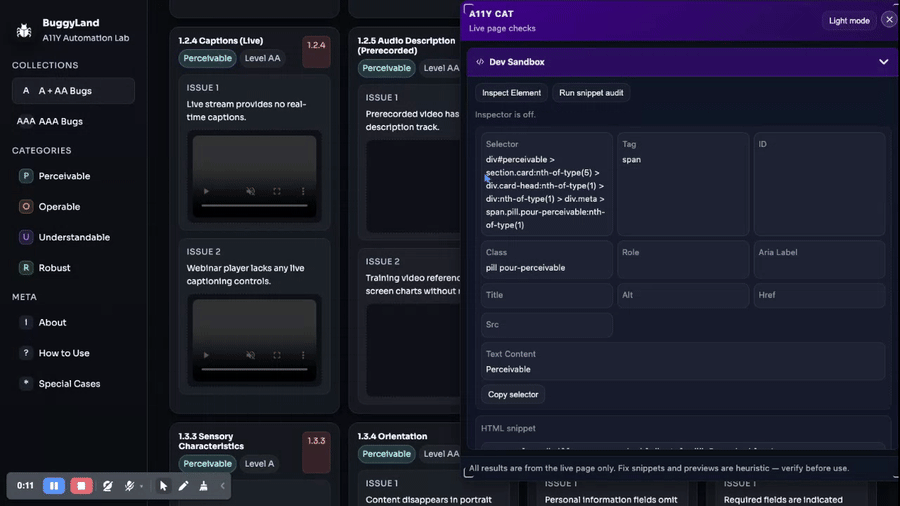
By “wider” I mean it kept picking up adjacent review surfaces. Not just one full-page scan, but metadata checks, social preview checks, broken links, alt text, headings, language, forms, buttons, dialogs, semantics inspection, search, and ticket handoff. Some of those lived in the early bookmarklet. Some arrived or matured later. But the overall direction is clear: every time the main scan hit a boundary, another focused workflow appeared nearby.
The April 8 “expand broken links & metadata, social preview card, UI polish, tests” commit is a good example. That is not core engine work in the narrow sense. It is the tool becoming more useful in the places developers and QA people often actually need help. Broken in-page fragments, same-origin link checks, Open Graph/Twitter metadata, thumbnail probing, grouped metadata gaps. Those things matter in real review even though they are not the headline accessibility engine story.
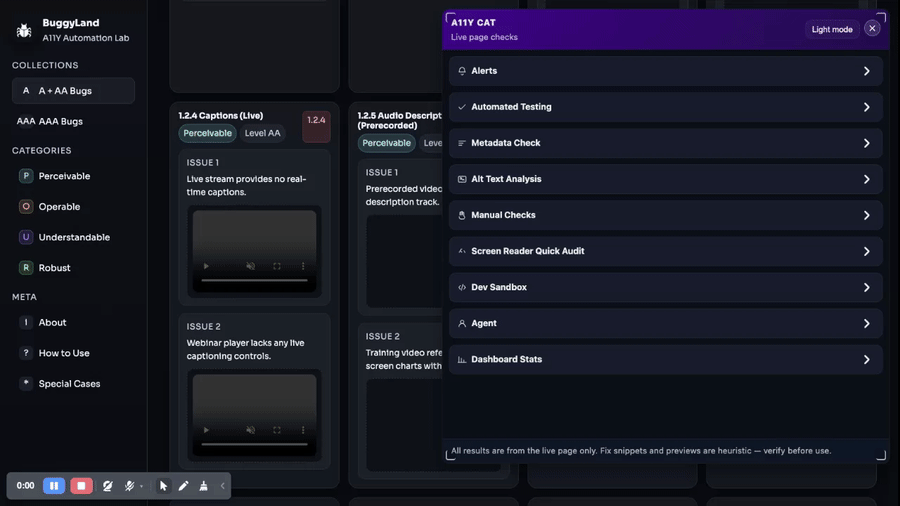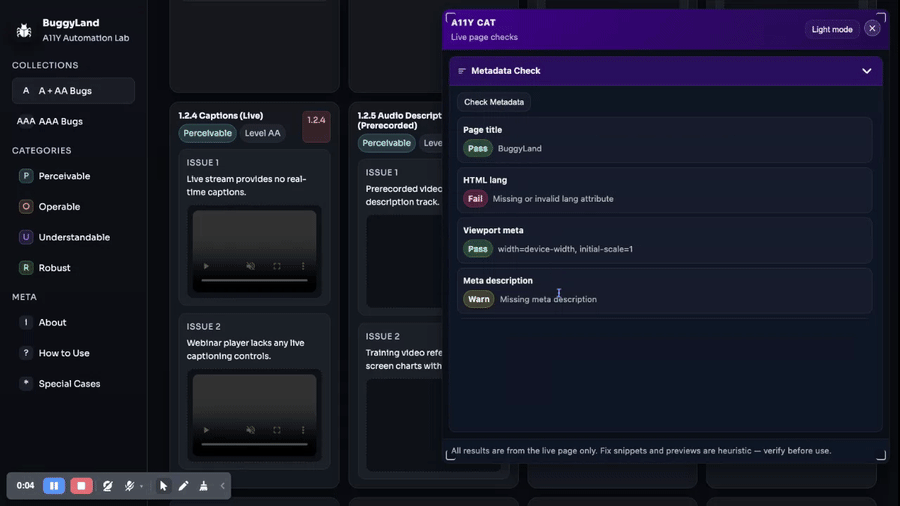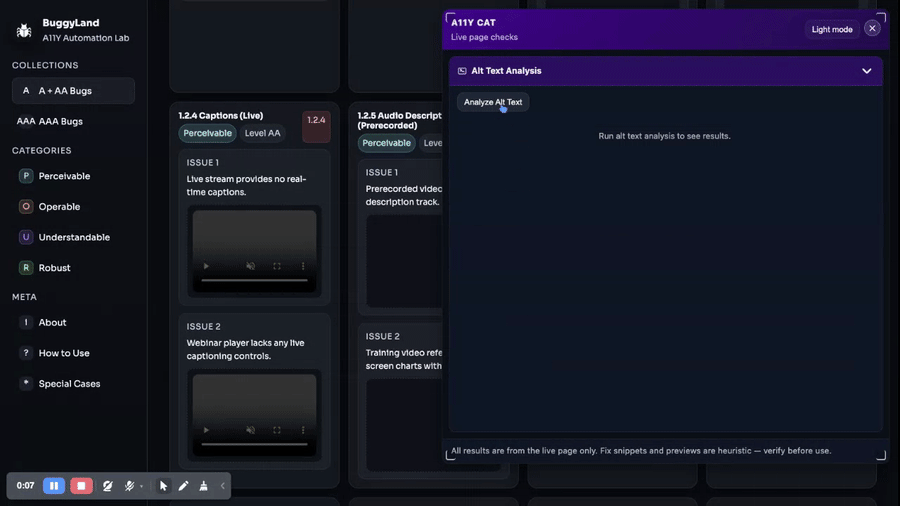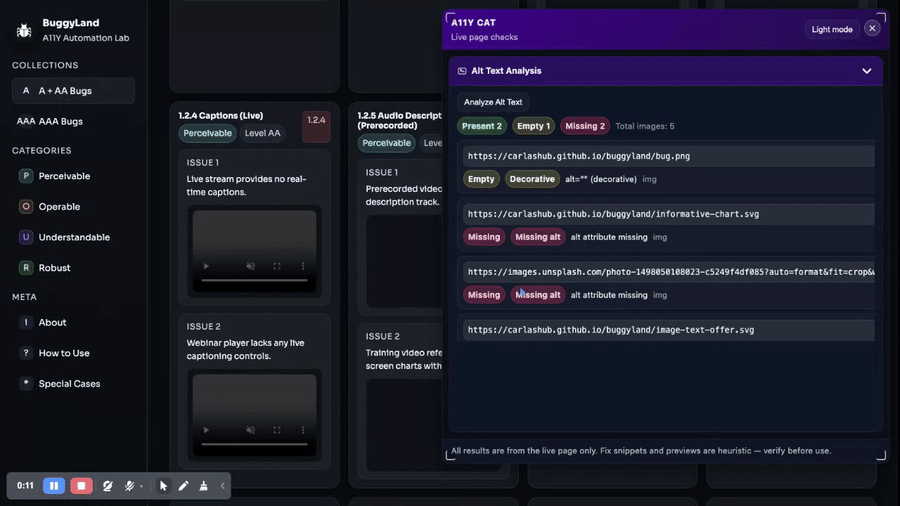
The command system pushes the same way. Once you have button, modal, semantics, form fields, fill, and submit, the tool is covering a lot of common page tasks from different angles. Later the language tab gets wired up more fully. The headings tab gets reshaped. Alt-text findings get highlight actions. Buttons, dialogs, and semantics all keep getting better targeted behavior.
I do not think this was random scope growth. I think it came from using the tool in context and noticing that accessibility review is rarely one clean scan followed by one fix. It is usually a cluster of smaller checks, confirmations, and handoffs.
The tradeoff is that widening the product surface creates a lot of consistency work later. Once you have all these sections, they need shared issue rendering, shared trust language, shared exports, shared diagnostics, shared UI hierarchy, and shared evidence rules. The repo spends a lot of April paying off exactly that cost.
So I read this phase as a good kind of mess. The builder was following real review needs, even if the architecture and wording had not fully caught up yet. The later tightening work only makes sense because the tool had already become broad enough to need it.
Visual evidence
Two repo-held visuals that show the widening surface especially well:
What I was really learning here
I was learning that accessibility review in the browser is not one job. It is a bunch of nearby jobs. The wider tool surface came from that reality, even though it created cleanup work later.
Evidence
- Commits:
fad0c23– broken links, metadata, social preview, and tests expandedb506753– language tab mismatch and spelling scans wired fully81fc57c– alt-text findings get highlight action- earlier command/inspection commits around February 15-16
- Files:
../../COMMAND_REFERENCE.md../../src/runtime/modules/name-analysis.js../../src/runtime/modules/language-analysis.js../../src/runtime/modules/headings-analysis.js../../tests/playwright/link-metadata-expanded.spec.js../../tests/playwright/meta-social-preview.spec.js../../tests/playwright/representative-pages.spec.js
- Inference:
- The framing that this came from “using the tool in context” is an inference from the kinds of workflows added, not from a written retrospective note.
