This was one of the first moments where the project stopped feeling like a passive report and started feeling like a browser-side helper.
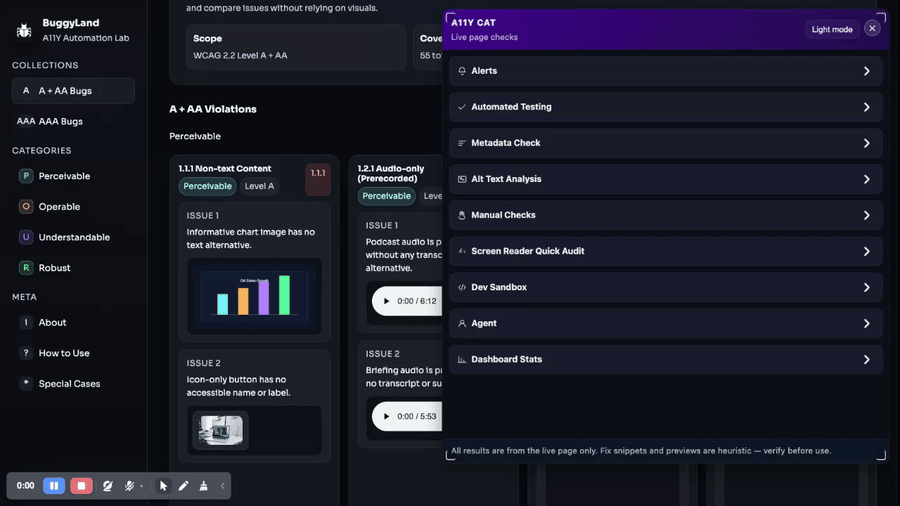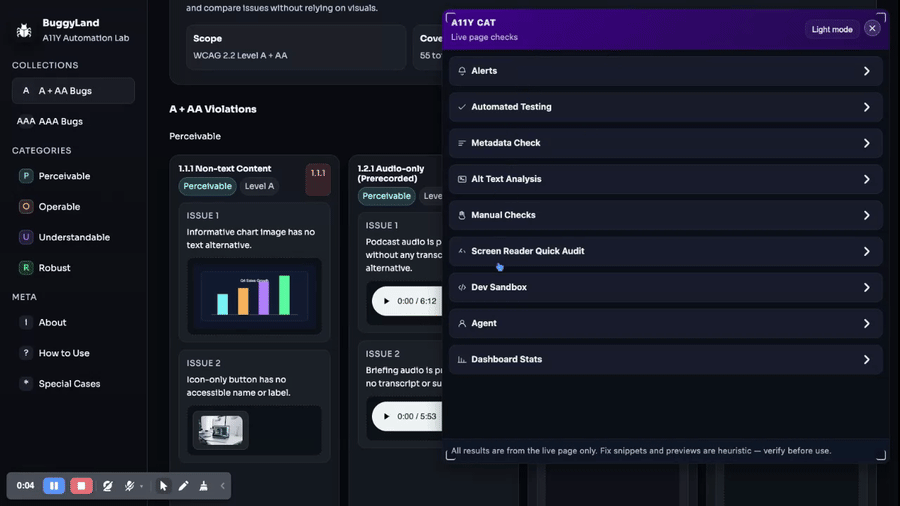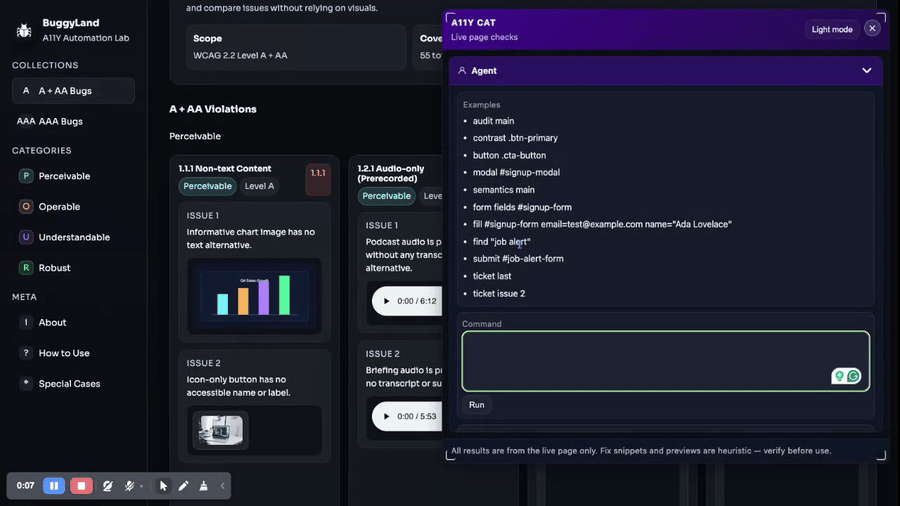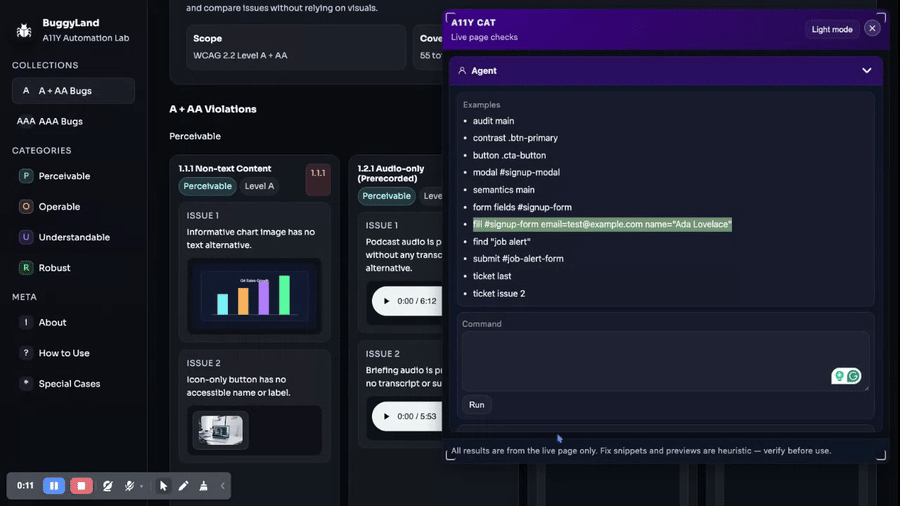
One of the biggest early jumps in A11Y Cat happens on February 15, when the bookmarklet gets ticket and agent features. That is a really revealing commit because it changes the posture of the UI.
Before that, the tool is mainly something you run and read. After that, it is something you talk to. The command surface adds verbs: audit, contrast, button, modal, semantics, form fields, fill, find, submit. Later, those commands get better docs, aliases, parser rules, and tests, but the important thing happens here. The audit panel stops being a destination for results and becomes an interface for follow-up work.
I like this part of the history because it feels like normal developer frustration turning into product design. If you are already on a page, once you have scan results you usually want the next step immediately. Show me this thing. Find that text. Inspect that button. Try this form. Draft a ticket from the issue I am looking at. That is all very practical. It is not abstract AI ambition. It is the kind of workflow stitching you end up wanting after a few repetitive audits.
The ticket feature tells the same story. Turning issues into Jira-friendly or Markdown-ready payloads means the tool is now thinking about handoff. Not just finding something, but moving it into the next system without retyping the important bits. Again, that is not glamorous. It is just the sort of pain that starts to stand out once you use a tool more than once.
There is also an interesting parser/tooling instinct here. The history around February 15 and 16 includes fixes like ignoring reportlet text when finding content, improving fill-command matching, and improving selector inference and fallbacks. That means the command system was not just added and left alone. It immediately ran into practical ambiguity. Text searches matched the tool’s own UI. Form fills needed quoted values. Form submission needed selector inference. The repo starts learning very quickly that “commands in theory” and “commands on real pages” are not the same thing.
By April 7, this whole area gets much more formal. COMMAND_REFERENCE.md appears, command-system Playwright coverage lands, fixtures are added, and the README gets explicit parser rules and examples. That later work makes the feature look more stable than it probably felt at the start. But the origin is easy to recognise: I had a panel full of information, and I wanted it to do something useful with less friction.
I also think this is one of the first places where A11Y Cat starts acting like a hybrid tool rather than a pure scanner. The commands sit across accessibility review, DOM inspection, form interaction, and workflow handoff. That blend is unusual. It is not a page inspector. It is not just an accessibility runner. It is not a ticket bot. It is all of those a little bit, and the later history keeps trying to make that mix less fragile.
The part I find most relatable is that the command system clearly grew from interaction with the tool, not from a grand architecture exercise. It has that feeling of “I kept wanting one more action while I was already in the page, so I kept adding one.”
Visual evidence
The repo includes a bookmarklet-era agent walkthrough that shows the command-tool direction clearly:
What I was really learning here
I was learning that once you build a browser tool people use during debugging, they immediately want it to help with the next task too. Results alone were not enough. The next actions had to be close by, or the workflow still felt clumsy.
Evidence
- Commits:
92ebc21– ticket and agent features added47f21e8– fill command matching improveddd48f73– reportlet text ignored during text findingdfaf15c– selector inference and fallback improved
- Files:
../../COMMAND_REFERENCE.md../../bookmarklet.js../../tests/playwright/command-system.spec.js../../tests/playwright/fixtures/command-fixture.html
- Docs:
README.mdrevisions around February 16 and April 7
- Inference:
- The idea that this grew from repetitive audit friction is an inference from the kinds of commands and follow-up fixes that appeared.
