I do not think I realised how much product shape was already in the first version until I looked back properly.
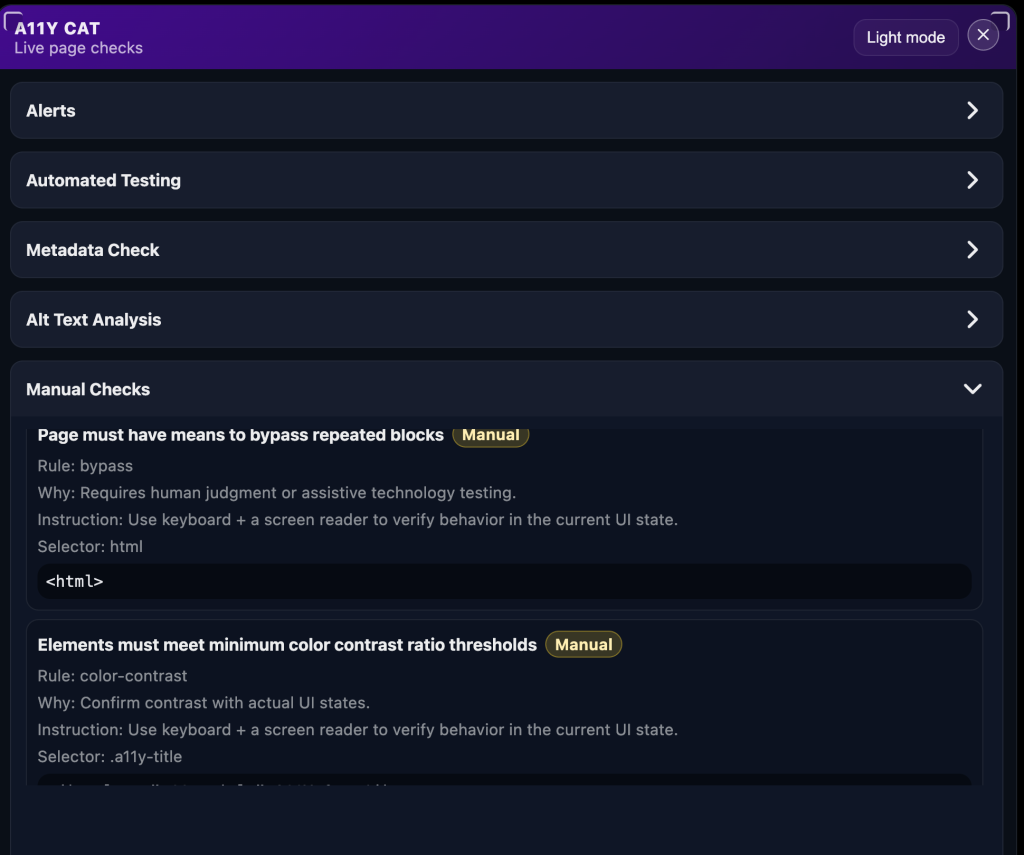
When people describe small accessibility tools, they often collapse them into one sentence: “it runs axe.” A11Y Cat never really fit that description, even in the first commit.
Yes, axe was there, and it mattered. The original architecture literally lists axe as the scanner and talks about WCAG A/AA rules. But the first public README also described metadata checks, alt-text analysis, manual checks, a developer sandbox, a screen reader quick audit, dashboard stats, and exports. That is already a broader opinion about what “page review” should mean.
I think that matters because it shows the problem was never only technical rule execution. It was also triage. It was context. It was “what else should I look at while I am already here?” The moment you add metadata, alt text, manual checks, and sandbox inspection, you are saying that the browser audit should support a real review workflow, not just produce a failure list.
The early screen reader quick audit is a good example. It was heuristic from the start. The old architecture doc calls it client-side DOM analysis for landmarks, heading hierarchy gaps, missing names, missing labels, duplicate names, and focus order hazards. That is a useful set of checks, but it is also one of the first places where this repo starts walking the line between deterministic findings and guidance. Later, the project gets much stricter about that line, but the tension already existed here.
The same thing is true for the developer sandbox. A sandbox sounds like a nice extra feature until you notice what it means: I do not just want page-wide output. I want scoped inspection. I want to grab a specific bit of the page and reason about it separately. That points toward a developer tool mindset very early on.
The dashboard stats tell a similar story. Totals, severity buckets, POUR buckets, risk estimates: those are summary views for humans trying to make sense of a messy page, not just raw engine data. Later, some of those summary ideas get reworked and made more disciplined, but the instinct to shape findings into something reviewable was already there.
Looking back, I think this was a useful kind of overreach. The repo was clearly not mature yet. It did not have the later testing depth, provenance model, release boundary docs, or strict issue taxonomy. But it was already trying to make accessibility review feel like a workflow with multiple angles, not a single pass/fail switch.
There is a downside to that kind of early ambition too. When you widen the surface this fast, it becomes easy to sound more certain than your implementation really is. The later history spends a lot of time fixing exactly that problem. Some things belonged in “confirmed issue” territory. Some belonged in “review this manually.” Some belonged in “the tool is helping, but it does not know enough to decide.” The first version had the breadth before it had the language.
Still, I would rather see that kind of early breadth than a thin wrapper pretending to be more than it is. At least the repo shows the real need. The builder was not just trying to render engine output in prettier cards. She was trying to make page review feel more complete from inside the browser.
Visual evidence
These launch-era bookmarklet screenshots back up the point that the tool already had multiple surfaces beyond a single issue list:
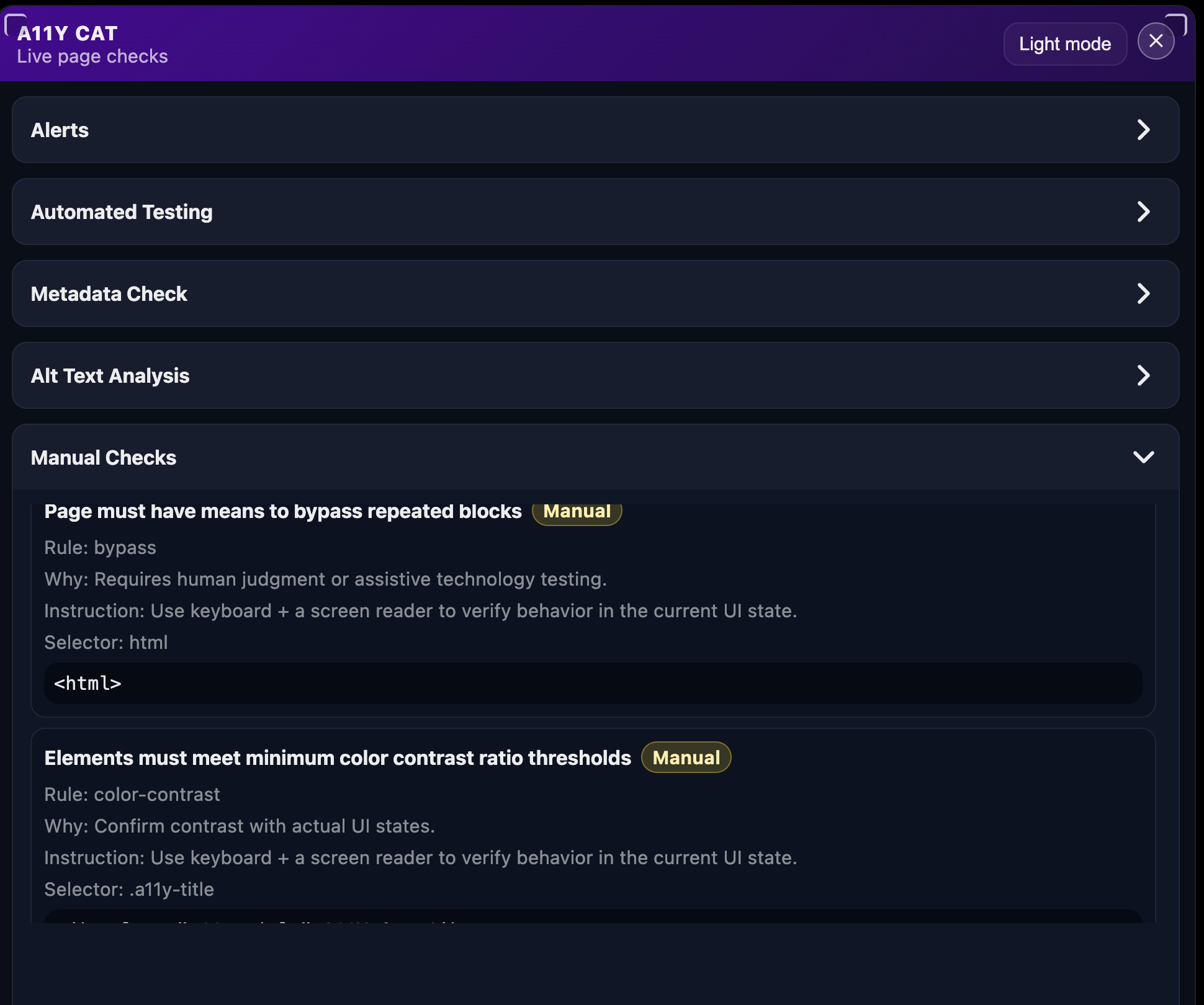
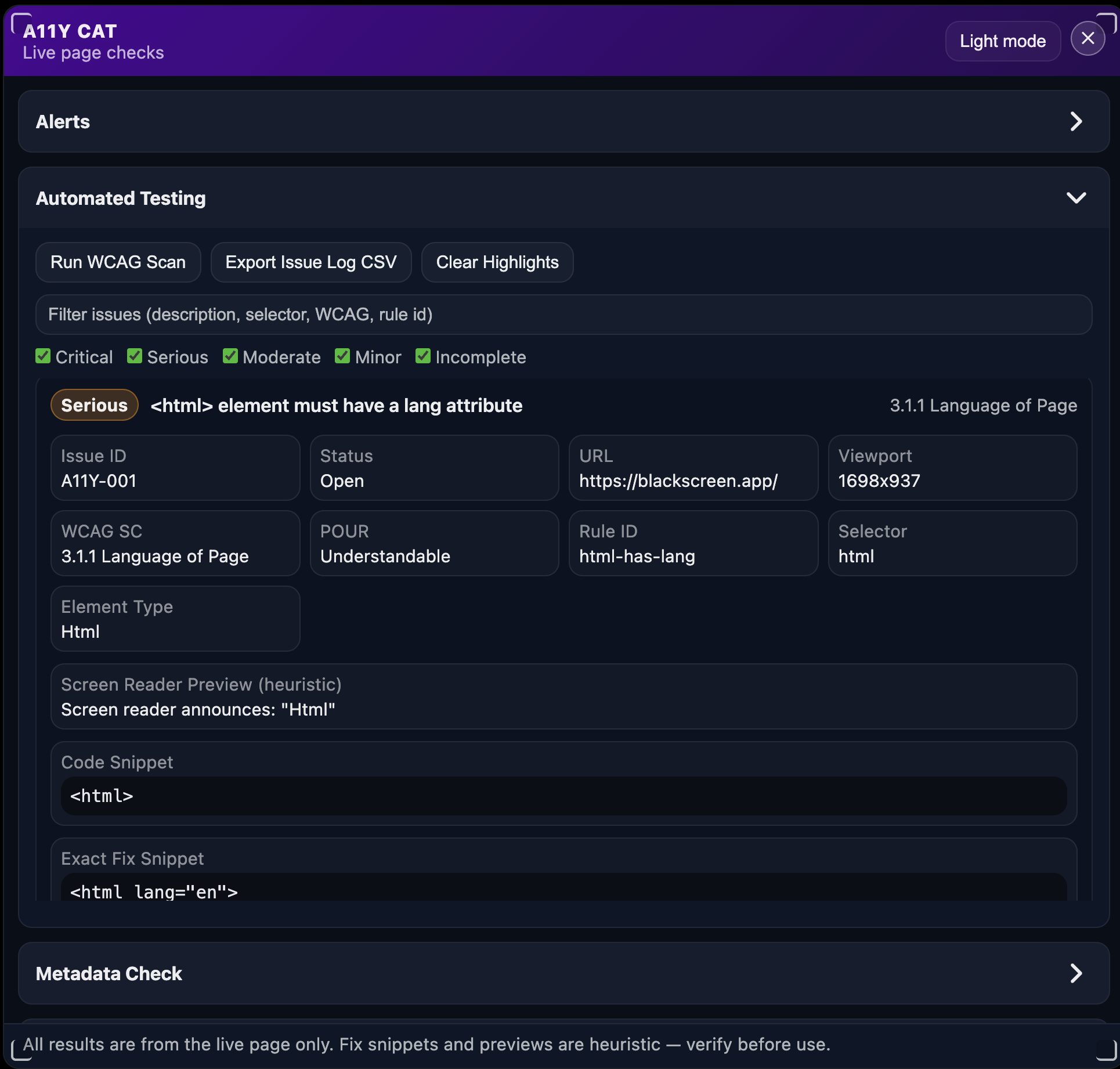
What I was really learning here
I was learning that “useful” and “certain” are not the same thing. A tool can help in a lot of places before it is honest enough about which of those places are deterministic and which are more like review prompts.
Evidence
- Commits:
1ef3d3c– first public bookmarklet package with broad feature claims already in place92ebc21– large early expansion of bookmarklet behavior62f9e76– improvements to agent UX, screen-reader audit, and contrast handling
- Files:
- original
README.mdandARCHITECTURE.mdfrom1ef3d3c ../../bookmarklet.js../../TECHNICAL_GUIDE.md
- original
- Implementation areas:
- early metadata, alt-text, manual-check, sandbox, and screen-reader flows inside
bookmarklet.js
- early metadata, alt-text, manual-check, sandbox, and screen-reader flows inside
- Inference:
- The framing that the repo had “breadth before language” is an inference based on later issue-taxonomy work and earlier broader feature descriptions.
